Mechanisms for Model Adaptation under Covariate and Concept Drift
Although Machine Learning algorithms are solving tasks of ever-increasing complexity, gathering data and building training sets remains an error-prone, costly, and difficult problem. AI2 researchers investigated different methods for reusing knowledge from related previously-solved tasks to reduce the amount of data required to learn a new task.
Reusing knowledge from previous tasks is challenging because covariate and concept drift might be present. For understanding those concepts, consider that we desire to train a model to predict whether if a person is likely to pay back a loan given to them. Imagine that, for learning this model, we gathered data from a loaner that primarily has customers over 65 years old. We then train the model on this data and realize that the model achieves 90% of accuracy. This model is then applied as a predictive source for many banks. However, the model is used for customers of any age and we later assess that the observed model accuracy was 40%! This degraded prediction quality was mainly due to a mismatch between the frequency of people over 65 years old in the data used for training in their frequency in the general population. This mismatch in frequencies is known as covariate shift. Now imagine we train a model sampling examples in a way that correctly reflects the Brazilian general population. However, the company is expanding business to Laos, and this same model is applied there. A similar decrease in accuracy is again observed. This time, the main reason for the decrease in accuracy was that the Laotian population is very different from the Brazilian one. For many reasons, the “rules” for predicting who will be able to pay their loans are different across these two countries. This issue is known as concept drift.
AI2 researchers have been working on methods to cope with those issues on two different fronts:
Tree-Adaptation Mechanism for Covariate and Concept Drift
Models based on decision trees have achieved state-of-the-art performance in many different tasks and domains. In order to make them more robust to covariate and concept drift, we proposed a method illustrated below.
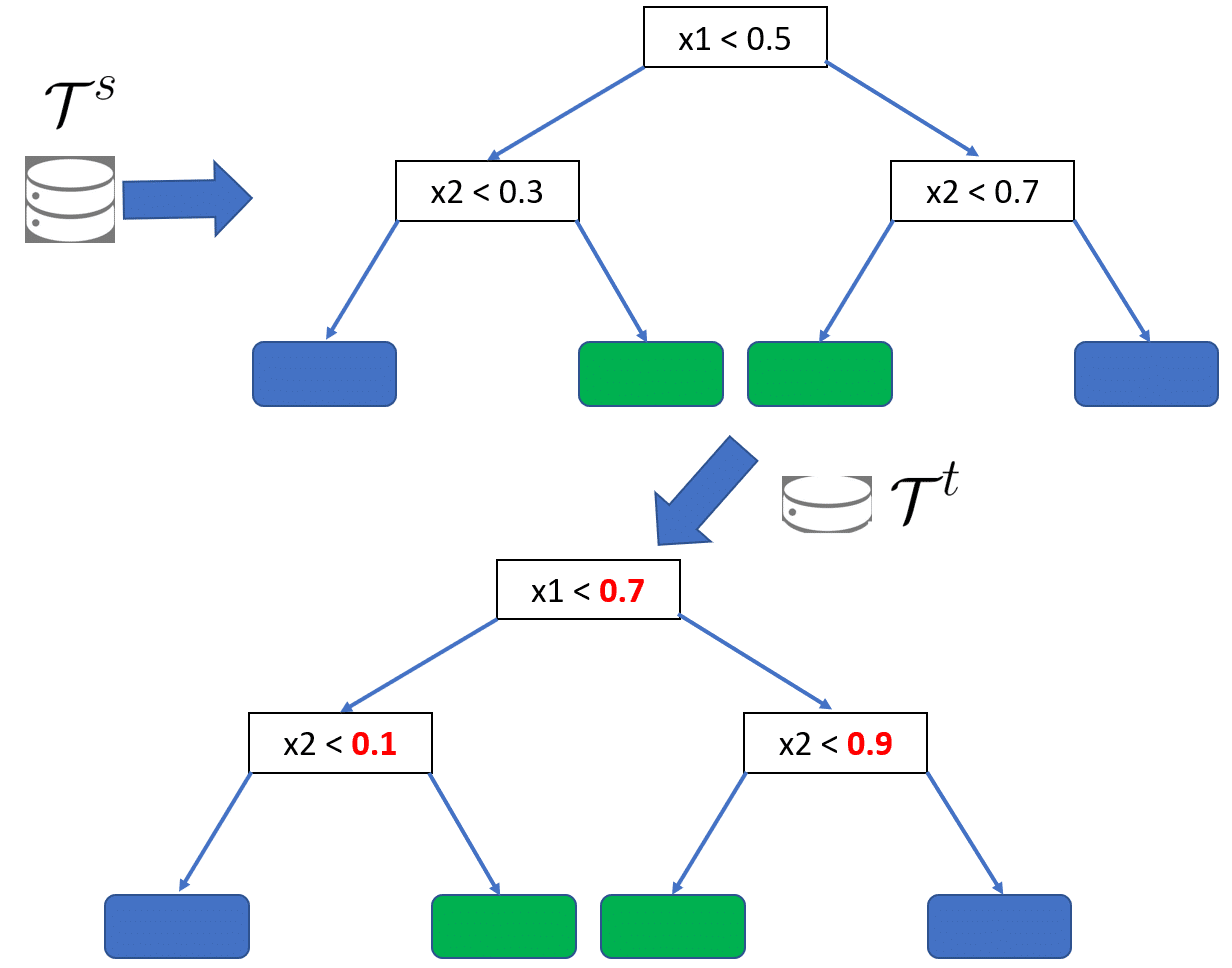
Every tree-based model has a set of “tests” to be performed to classify a sample. In the example below the variable x1 is tested with a threshold of 0.5. If x1 is higher than 0.5, the model proceeds to the next test on the right subtree (x2 < 0.7). Otherwise, the model proceeds to the left. Multiple tests are performed until a final classification is assigned to the sample. However, in the presence of covariate and/or concept drift, those thresholds might not be valid anymore.
We proposed an approach to recalculate those thresholds according to the data in the new task. The data in the new task is analyzed and the tree thresholds are adapted to improve performance accounting for covariate and concept drift.
Model Refinement
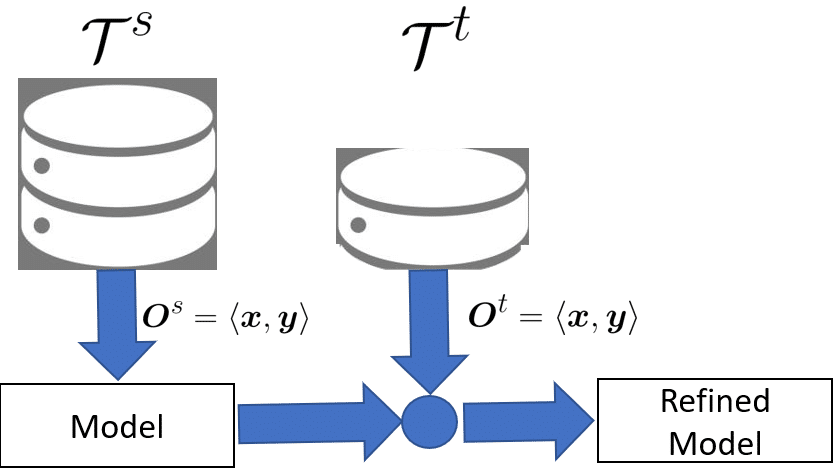
This recalculation can be performed in two modalities. In the Model Refinement, we have a small number of labeled samples in the new task. In the above example, it would correspond to having data from a small number of loans in Laos, and we would use them to refine the Brazilian model.
Model Adaptation
In the Model Adaptation, we assume no labeled samples are available from the new task, which would correspond to adapting the model without any example of loans in Laos.
Data Mapping for Model Adaptation
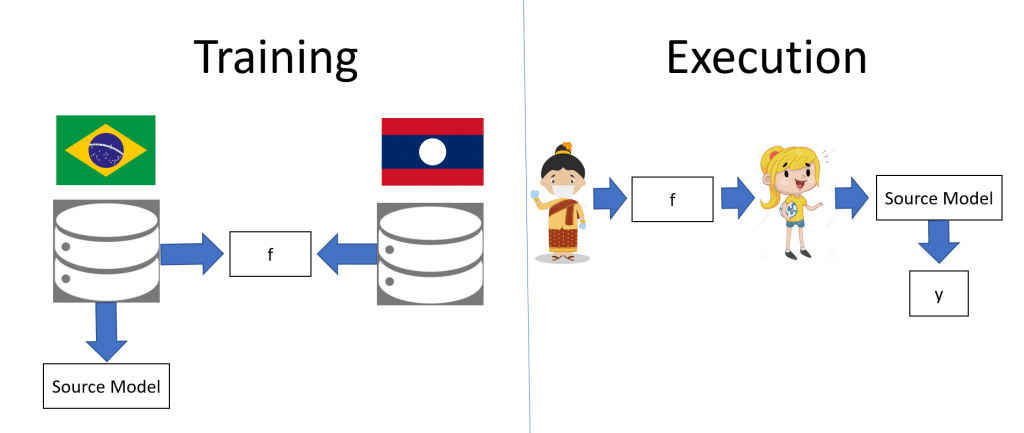
Instead of adapting trained models across tasks, we train a mapping function to learn how different is the data in two different but related tasks. In the example above, the mapping function f is trained to learn through data how different the Brazilian and Laotian populations are.
Later, model f is used to reuse the loan model learned in Brazil for the Laotian population. When the model needs to be used for a Laotian customer, f maps the customer to his/her “correspondent” in the Brazilian population. Then, the model trained in Brazil can be directly used.
Neural Networks are used to learn the mapping function.
Papers
Leno Da Silva, F. et al., (2021). A Tree-Adaptation Mechanism for Covariate and Concept Drift [Oral Presentation]. International Conference on Machine Learning Conference: LatinX in AI (LXAI) Research Workshop 2021, Virtual.
Leno Da Silva, F. et al., (2021). GAN-based Data Mapping for Model Adaptation [Oral Presentation]. International Conference on Machine Learning Conference: LatinX in AI (LXAI) Research Workshop 2021, Virtual.





