In a paper published recently, researchers from MIT’s Computer Science & Artificial Intelligence Laboratory have proposed a method for learning a face from audio recordings of that person speaking.
The goal of the project was to investigate how much information about a person’s looks can be inferred from the way they speak. Researchers proposed a neural network architecture designed specifically to perform the task of facial reconstruction from audio.
They used natural videos of people speaking collected from Youtube and other internet sources. The proposed approach is self-supervised and researchers exploit the natural synchronization of faces and speech in videos to learn the reconstruction of a person’s face from speech segments.

In their architecture, researchers utilize facial recognition pre-trained models as well as a face decoder model which takes as an input a latent vector and outputs an image with a reconstruction.
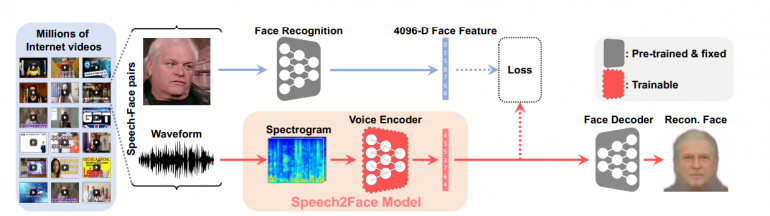
From the videos, they extract speech-face pairs, which are fed into two branches of the architecture. The images are encoded into a latent vector using the pre-trained face recognition model, whilst the waveform is fed into a voice encoder in a form of a spectrogram, in order to utilize the power of convolutional architectures. The encoded vector from the voice encoder is fed into the face decoder to obtain the final face reconstruction.
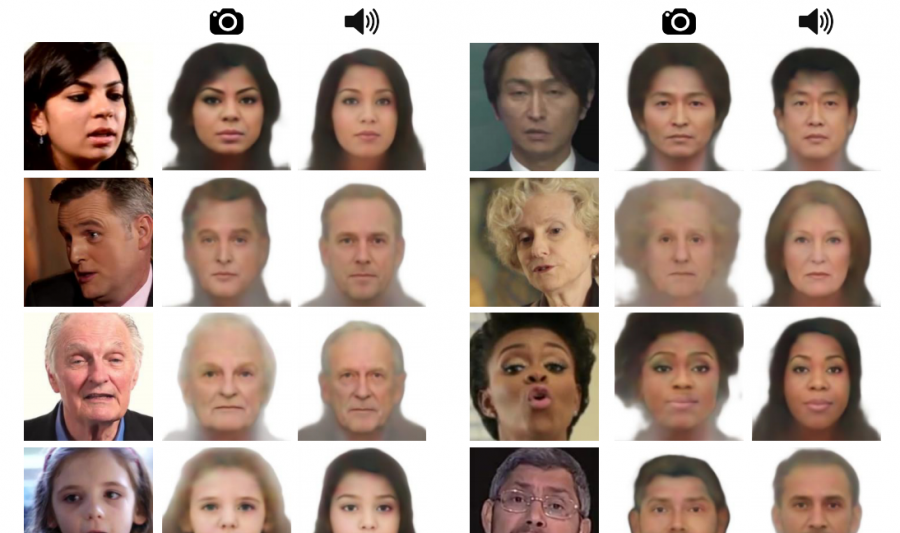
The evaluations of the method show that it is able to predict plausible faces with consistent facial features with the ones from real images. Researchers created a page with supplementary material where sample outputs of the method can be found. The paper was accepted as a conference paper at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019.





